[OS] CPU 스케줄링
CPU 스케줄링 기본 개념, FCFS, SJF, 우선순위 스케줄링, Round Robin, 멀티레벨 큐/피드백 큐, 멀티프로세서·스레드·실시간 스케줄링, OS별 사례
1. CPU 스케줄링 개요 및 기본 개념
CPU 스케줄링이란 멀티프로그래밍 환경에서 메모리에 올라와 있는 여러 프로세스 중 어느 프로세스에 CPU를 할당할지 순서를 결정하는 작업이다.
CPU 관점에서는 “어느 프로세스를 다음에 실행할 것인가”를 결정하는 것이며, 작업(Job) 관점에서는 “어느 작업을 CPU에 던져줄 것인가”로도 표현할 수 있어 잡 스케줄링(Job Scheduling)이라고도 불린다.
현대 시스템은 대부분 멀티프로그래밍 방식으로 동작하므로 CPU는 항상 여러 선택지를 갖게 되며, 스케줄링의 질에 따라 시스템 성능이 크게 달라진다.
- 멀티프로그래밍: 메모리 위에 여러 프로세스가 동시에 올라와 있는 상태
- CPU 버스트(CPU Burst): 프로세스가 CPU를 사용하여 연산을 수행하는 구간
- I/O 버스트(I/O Burst): 프로세스가 I/O 작업을 수행하는 구간
- 프로세스는 CPU 버스트와 I/O 버스트를 반복하며 실행되다가 종료됨
- I/O 작업은 CPU 연산에 비해 상대적으로 매우 느리므로, I/O 대기 중인 프로세스를 기다리지 않고 다른 프로세스를 CPU에 할당하여 CPU 이용률을 높임
- 통계적으로 CPU 버스트 타임이 약 3밀리초 정도인 경우가 가장 빈번하게 관찰됨 → CPU를 오래 점유하지 않고 짧게 사용 후 I/O 작업으로 전환하는 패턴이 일반적
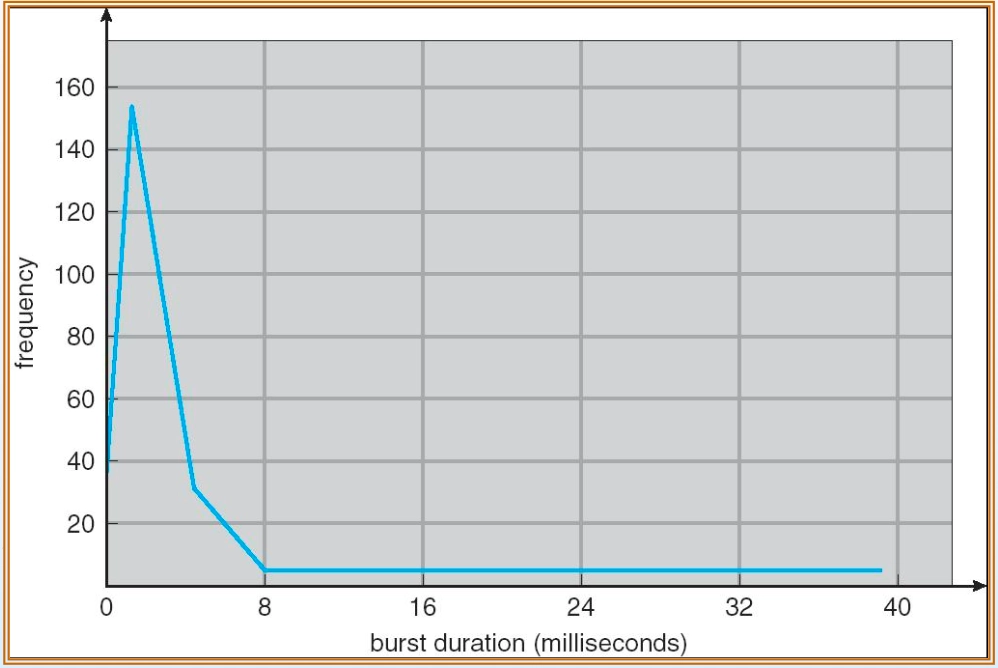 CPU burst duration histogram
CPU burst duration histogram
2. 스케줄링 시점 및 디스패처
CPU 스케줄링이 발생하는 시점은 크게 4가지로 구분된다. 이 중 프로세스 상태 전이의 성격에 따라 비선점(Non-preemptive) 방식과 선점(Preemptive) 방식으로 나뉜다. 스케줄링 결과로 선택된 프로세스를 실제로 CPU에 올리는 작업은 디스패처(Dispatcher)가 담당하며, 이 과정에서 발생하는 지연 시간을 디스패치 레이턴시(Dispatch Latency)라고 한다.
- 스케줄링 발생 시점 4가지:
- Running → Waiting 상태 전이 (주로 I/O 요청 발생) → Non-preemptive
- Running → Ready 상태 전이 (인터럽트 발생) → Preemptive
- Waiting → Ready 상태 전이 (I/O 완료) → Preemptive
- 프로세스 종료(Terminate) → Non-preemptive
- Non-preemptive(비선점): 현재 CPU가 처리 중인 프로세스를 중단시키지 않음 (시점 1, 4)
- Preemptive(선점): Ready 큐에 변동이 생겼을 때 현재 실행 중인 프로세스를 중단하고 재스케줄링 가능 (시점 2, 3)
- 디스패처(Dispatcher)의 역할:
- 컨텍스트 스위칭(Context Switching): 현재 프로세스의 PCB 저장 → 새 프로세스의 PCB 복구
- 사용자 모드(User Mode)로 전환
- 새로 선택된 프로세스의 중단 시점부터 실행 재개
- 디스패치 레이턴시(Dispatch Latency): 디스패처가 컨텍스트 스위칭 등 디스패치 작업을 수행하는 데 걸리는 시간
3. 스케줄링 기준(Scheduling Criteria)
스케줄링 알고리즘의 성능을 평가하고 목표를 설정하기 위한 기준이 5~6가지 존재한다. 각 기준은 최대화 또는 최소화 방향이 명확히 정해져 있으며, 어떤 기준을 우선시하느냐에 따라 적합한 알고리즘이 달라진다.
| 기준 | 설명 | 목표 |
|---|---|---|
| CPU Utilization (CPU 이용률) | CPU가 유용한 작업을 수행하는 비율 | 최대화 |
| Throughput (처리량) | 단위 시간당 완료되는 프로세스 수 | 최대화 |
| Turnaround Time (반환 시간) | 프로세스 제출부터 완료까지 걸리는 총 시간 | 최소화 |
| Waiting Time (대기 시간) | Ready 큐에서 대기하는 시간의 합 | 최소화 |
| Response Time (응답 시간) | 요청 후 첫 번째 응답이 나올 때까지 걸리는 시간 | 최소화 |
- Waiting Time은 Ready 큐 안에서 기다리는 시간만을 의미하며, 짧을수록 CPU를 빨리 할당받았음을 의미함
- Response Time은 프로세스가 완료될 때까지의 시간(Turnaround Time)과 구별됨 — 첫 반응이 나오는 시점까지의 시간
4. FCFS(First-Come, First-Served) 알고리즘
FCFS는 Ready 큐에 도착한 순서대로 CPU를 할당하는 가장 단순한 스케줄링 알고리즘이다.
구현이 간단하지만, 처리 시간이 긴 프로세스가 먼저 도착할 경우 뒤에 대기하는 짧은 프로세스들의 평균 대기 시간이 크게 증가하는 Convoy Effect(호위 효과)가 발생한다.
- 동작 방식: Ready 큐 도착 순서대로 CPU 할당
예시 1 (프로세스 도착 순서 P1, P2, P3)
 FCFS example: P1, P2, P3 도착 순서
FCFS example: P1, P2, P3 도착 순서- 평균 대기 시간 = (0 + 24 + 27) / 3 = 17
예시 2 (프로세스 도착 순서 P2, P3, P1)
 FCFS example: P2, P3, P1 도착 순서
FCFS example: P2, P3, P1 도착 순서- 평균 대기 시간 = (0 + 3 + 6) / 3 = 3
- Convoy Effect: 처리 시간이 긴 프로세스 뒤에 짧은 프로세스들이 줄지어 대기하면서 평균 대기 시간이 증가하는 현상
- 결론: 짧은 작업을 먼저 처리할수록 평균 대기 시간이 줄어듦 → SJF 알고리즘의 동기
5. SJF(Shortest Job First) 알고리즘 및 CPU 버스트 예측
SJF 알고리즘은 CPU 버스트 타임이 가장 짧은 프로세스를 우선 처리하는 방식으로, 이론적으로 평균 대기 시간을 최소화하는 최적 알고리즘으로 알려져 있다.
비선점(Non-preemptive)과 선점(Preemptive, SRT) 두 가지 방식이 존재하며, 선점 방식은 컨텍스트 스위칭 횟수가 증가하는 트레이드오프가 있다.
또한 미래의 CPU 버스트 타임을 알 수 없으므로 지수 평균(Exponential Averaging)을 통해 예측한다.
- Non-preemptive SJF: CPU가 처리 중인 프로세스는 중단하지 않고, Ready 큐 내 프로세스 중 버스트 타임이 가장 짧은 것을 다음에 선택
- Preemptive SJF (SRT, Shortest Remaining Time First): 현재 처리 중인 프로세스의 남은 작업량까지 포함하여 스케줄링 → 더 짧은 프로세스가 도착하면 현재 프로세스를 선점
Non-preemptive 예시:
 SJF Non-preemptive scheduling example
SJF Non-preemptive scheduling example- 평균 대기 시간 = 4
Preemptive(SRT) 예시:
 SJF Preemptive (Shortest Remaining Time) example
SJF Preemptive (Shortest Remaining Time) example- 평균 대기 시간 = 3 (더 낮음)
- 단, 컨텍스트 스위칭 횟수: Non-preemptive 3회 → Preemptive 5회로 증가
- 트레이드오프: 선점 방식은 평균 대기 시간은 줄지만 컨텍스트 스위칭 오버헤드가 증가함
- CPU 버스트 예측 (지수 평균):
- 공식: τ_(n+1) = α × t_(n) + (1 - α) × τ_(n)
- τ_(n+1): 다음 상태의 예측값
- t_(n): 현재 상태의 실측값
- τ_(n): 현재 상태의 예측값
- α: 0 ≤ α ≤ 1 (비중 조절 파라미터)
- α = 0이면 과거 예측값만 반영, α = 1이면 현재 실측값만 반영
α와 (1-α)의 거듭제곱 형태로 과거로 갈수록 영향력이 감소함
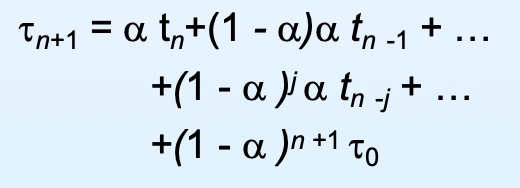 Exponential averaging for CPU burst prediction
Exponential averaging for CPU burst prediction- CPU 버스트 타임은 미래 얘기다. 앞으로 CPU를 할당받으면 이만큼 쓸 것 같다는 예측이기 때문에 측정이 아니라 예측을 할 수밖에 없다.
- 공식: τ_(n+1) = α × t_(n) + (1 - α) × τ_(n)
6. 우선순위 스케줄링(Priority Scheduling) 및 Starvation
우선순위 스케줄링은 각 프로세스에 우선순위 번호를 부여하고, 번호가 낮을수록(또는 높을수록, 정의에 따라 다름) 우선순위가 높은 프로세스를 먼저 CPU에 할당하는 방식이다.
SJF 알고리즘도 작업량이 작을수록 우선순위가 높다고 정의하면 우선순위 스케줄링의 일종으로 볼 수 있다. 이 방식의 주요 문제점은 기아(Starvation)현상이며, 이를 해결하기 위해 에이징(Aging) 기법을 사용한다.
- 동작 방식: 우선순위 번호가 낮은(높은 우선순위) 프로세스를 먼저 CPU에 할당
- Preemptive 방식: 새로운 프로세스가 Ready 큐에 도착했을 때, 현재 실행 중인 프로세스의 우선순위와 비교하여 더 높은 우선순위의 프로세스로 선점 가능
- Non-preemptive 방식: 현재 CPU가 처리 중인 프로세스는 건드리지 않고, Ready 큐 내에서만 우선순위 기반 스케줄링 수행
- 문제 - Starvation(기아 현상): 우선순위가 낮은 프로세스가 높은 우선순위 프로세스들에 의해 계속 밀려 CPU를 할당받지 못하는 현상
- 해결 - Aging(에이징) 기법: 일정 시간 동안 CPU를 할당받지 못한 프로세스의 우선순위를 단계적으로 높여주어 결국 CPU를 할당받을 수 있도록 보장
7. 라운드 로빈(Round Robin) 스케줄링
라운드 로빈은 Ready 큐에 도착한 순서대로 CPU를 할당하되, 각 프로세스가 CPU를 사용할 수 있는 최대 시간인 타임 퀀텀(Time Quantum)을 설정하여 해당 시간 내에 작업이 완료되지 않으면 다시 Ready 큐의 맨 뒤로 돌아가 대기하는 방식이다. 응답 시간(Response Time) 측면에서 우수하며, 대화형 시스템에 적합하다.
- 타임 퀀텀(Time Quantum): CPU를 한 번에 사용할 수 있는 최대 시간 단위
- 타임 퀀텀이 클수록: FCFS와 유사하게 동작 (대부분의 프로세스가 한 번에 완료)
- 타임 퀀텀이 작을수록: 컨텍스트 스위칭이 자주 발생하여 오버헤드 증가
예시 (타임 퀀텀 = 20):
 Round Robin scheduling with time quantum = 20
Round Robin scheduling with time quantum = 20- P1: 20 처리 후 뒤로 이동 (잔여 33)
- P2: 17 처리 후 완료 (타임 퀀텀 내 종료)
- P3: 20 처리 후 뒤로 이동 (잔여 48)
- P4: 20 처리 후 뒤로 이동 (잔여 4) → 이후 4 처리 완료
- 이후 P1, P3 순서로 잔여 작업 처리
- SJF vs. Round Robin 비교:
- Turnaround Time: SJF가 우수
- Response Time: Round Robin이 우수 (중간중간 응답 발생)
Rule of Thumb: 전체 프로세스의 약 90%가 한 번의 타임 퀀텀 내에 완료될 수 있는 값으로 타임 퀀텀을 설정하는 것이 성능상 최적
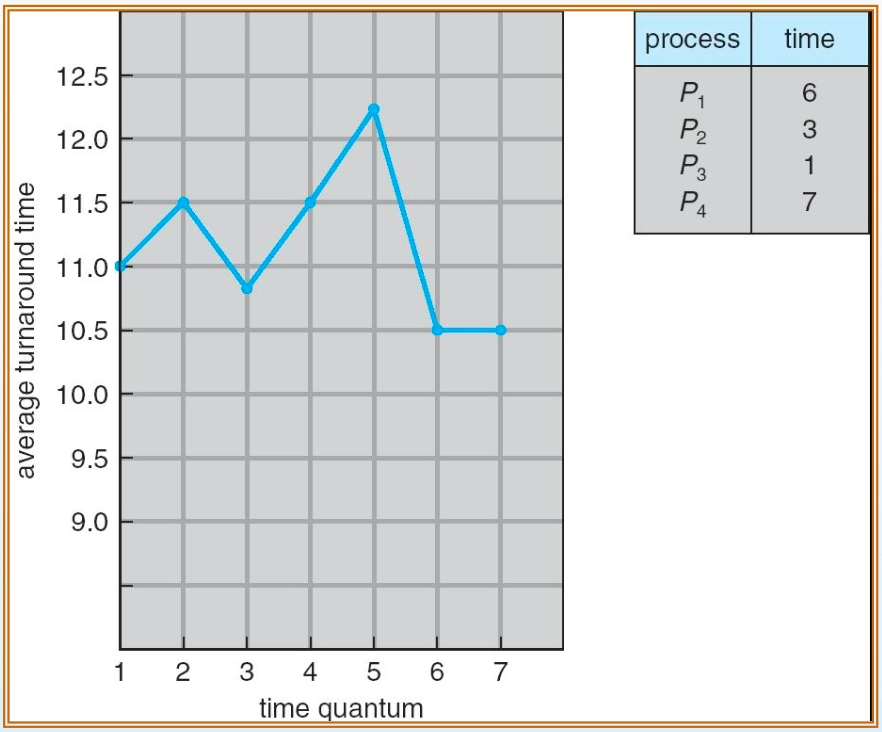 Turnaround time varies with time quantum
Turnaround time varies with time quantum- Turnaround Time과 타임 퀀텀의 관계: 타임 퀀텀 증가가 반드시 Turnaround Time 감소로 이어지지 않으며, 일관성 없는 패턴을 보임
8. 멀티레벨 큐 (Multilevel Queue)
멀티레벨 큐는 레디 큐를 성격에 따라 여러 개로 분리하여 운영하는 방식이다. 대표적으로 인터랙티브 작업을 위한 포그라운드 큐와 배치 작업을 위한 백그라운드 큐로 나뉘며, 각 큐마다 서로 다른 스케줄링 알고리즘을 적용한다.
- 포그라운드 큐: 라운드 로빈(Round Robin) 알고리즘 적용 → 응답 시간(Response Time) 향상
- 백그라운드 큐: FCFS(First Come First Served) 알고리즘 적용 → 순서대로 처리
- 큐 간 CPU 할당 방식:
- 방법 1: 포그라운드 큐 작업을 모두 처리한 후 백그라운드 큐 처리 → 스타베이션(Starvation, 기아) 문제 발생 가능
- 방법 2: CPU 타임을 비율로 분배 (예: 포그라운드 80%, 백그라운드 20%)
- 우선순위 계층 예시 (5단계): 시스템 프로세스 → 인터랙티브 프로세스 → 인터랙티브 에디팅 프로세스 → 배치 프로세스 → 스튜던트(실습용) 프로세스 순으로 우선순위 감소
 Multilevel queue scheduling
Multilevel queue scheduling
9. 멀티레벨 피드백 큐 (Multilevel Feedback Queue)
멀티레벨 피드백 큐는 기존 멀티레벨 큐에 큐 간 이동(피드백) 경로를 추가하여 스타베이션 문제를 해결한 방식이다. 프로세스가 여러 큐 사이를 이동할 수 있으며, 특히 하위 큐에서 상위 큐로 올라가는 경로를 통해 에이징(Aging) 기법을 구현한다.
- 에이징(Aging): 일정 시간 동안 CPU를 할당받지 못한 프로세스의 우선순위를 점진적으로 높여 스타베이션을 방지하는 기법
구현 예시 (3단계 큐):
 Multilevel feedback queue with 3 levels
Multilevel feedback queue with 3 levels- Q0: 라운드 로빈, 타임 퀀텀 8ms → 미완료 시 Q1으로 강등(Demote)
- Q1: 라운드 로빈, 타임 퀀텀 16ms → 미완료 시 Q2로 강등
- Q2: FCFS 적용
- 설계 시 고려 파라미터:
- 큐의 개수
- 각 큐의 스케줄링 알고리즘
- 강등(Demote) 기준
- 승격(Upgrade, 에이징) 방법
- I/O 완료 또는 인터럽트 발생 후 프로세스를 어느 큐에 재삽입할지
- 알고리즘적 특성: SJF(Shortest Job First) 및 우선순위 기반 알고리즘으로도 해석 가능. 작업량이 작을수록 상위 큐에서 빨리 종료되므로 사실상 짧은 작업 우선 처리
10. 멀티프로세서 스케줄링 (Multiprocessor Scheduling)
CPU가 여러 개인 환경에서는 단일 CPU 환경보다 스케줄링이 복잡해진다. 크게 비대칭(Asymmetric)과 대칭(Symmetric) 방식으로 구분된다.
- 비대칭 멀티프로세싱(Asymmetric Multiprocessing): 하나의 마스터 CPU가 스케줄링을 전담하고 나머지 슬레이브 CPU는 할당된 작업만 처리 → 푸시(Push) 방식 (마스터가 일감을 밀어줌)
- 대칭 멀티프로세싱(Symmetric Multiprocessing, SMP): 각 CPU가 독립적으로 스케줄링 수행 → 풀(Pull) 방식 (각 CPU가 유휴 상태가 되면 스스로 일감을 가져옴)
- 프로세서 어피니티(Processor Affinity): 특정 프로세스를 이전에 실행했던 CPU에 재할당하여 캐시 히트율(Cache Hit Ratio)을 높이는 기법
- 하드 어피니티(Hard Affinity): 동일 CPU 재할당 보장
- 소프트 어피니티(Soft Affinity): 동일 CPU 재할당을 노력하되 보장하지 않음
11. 스레드 스케줄링 (Thread Scheduling)
CPU는 커널 레벨 스레드만 직접 인식하며, 유저 레벨 스레드는 LWP(Lightweight Process)를 통해 간접적으로 스케줄링된다.
 Thread scheduling: user threads mapped to kernel threads via LWP
Thread scheduling: user threads mapped to kernel threads via LWP
- 로컬 스케줄링(Local Scheduling): 유저 레벨 스레드가 LWP(가상 프로세스)에 할당되는 과정. 유저 스레드 라이브러리 수준에서 발생
- 글로벌 스케줄링(Global Scheduling): 커널이 여러 커널 레벨 스레드 중 어느 것을 CPU에 할당할지 결정하는 과정
12. 실시간 스케줄링 (Real-Time Scheduling)
실시간 시스템은 작업 완료 시간 보장 여부에 따라 두 가지로 분류된다.
- 하드 리얼타임(Hard Real-Time): 정해진 시간 내 작업 완료를 반드시 보장
- 소프트 리얼타임(Soft Real-Time): 실시간 작업에 최고 우선순위를 부여하되 완료 시간 보장 불가
13. 운영체제별 스케줄링 사례 연구
실제 운영체제에서 CPU 스케줄링이 어떻게 구현되는지를 Solaris 2, Windows XP, Linux를 통해 살펴본다.
Solaris 2
 Solaris 2 dispatch table (part 1)
Solaris 2 dispatch table (part 1)
 Solaris 2 dispatch table (part 2)
Solaris 2 dispatch table (part 2)
- 우선순위 클래스: 리얼타임 > 시스템 > 인터랙티브/타임셰어링
- 디스패치 테이블: 우선순위, 타임 퀀텀, 타임 퀀텀 만료 후 우선순위, I/O 완료 후 우선순위 정의
- 우선순위 ↑ → 타임 퀀텀 ↓ (반비례): 예) 우선순위 59 → 타임 퀀텀 20ms, 우선순위 낮음 → 타임 퀀텀 200ms
- I/O 완료 프로세스에 높은 우선순위(50 이상) 재부여 → 즉시 CPU 할당 가능
- 결과: 인터랙티브 작업의 응답 시간(Response Time) 향상, CPU 집약 작업의 처리량(Throughput) 향상
Windows XP
 Windows XP priority classes
Windows XP priority classes
- 6개 우선순위 클래스: Real-Time > High > Above Normal > Normal > Below Normal > Idle
- 각 클래스 내 7단계 세분화 (예: 리얼타임 클래스 내 Time-Critical=31, Highest=26, … Idle=16)
Linux
 Linux scheduling: credit-based time-sharing
Linux scheduling: credit-based time-sharing
 Linux scheduling: active and expired arrays
Linux scheduling: active and expired arrays
- 타임셰어링: 크레딧(Credit) 기반 스케줄링 → 크레딧 가장 높은 프로세스 선택, 실행 시 크레딧 차감, 전체 0이 되면 우선순위·히스토리 반영하여 재할당
- 리얼타임: 소프트 리얼타임만 지원, FCFS 및 라운드 로빈 두 클래스 제공
- 우선순위 0(최고, 리얼타임) → 타임 퀀텀 200ms, 우선순위 높을수록 타임 퀀텀 크게 부여
- 액티브 큐(Active Array) / 만료 큐(Expired Array): 타임 퀀텀 내 미완료 작업은 Expired Array의 동일 우선순위 큐로 이동
14. 스케줄링 알고리즘 평가 방법 (Algorithm Evaluation)
스케줄링 알고리즘의 성능을 비교·평가하는 세 가지 방법론을 다룬다.
결정론적 모델(Deterministic Model): 주어진 프로세스의 도착 시간·버스트 시간을 바탕으로 Gantt Chart를 작성하고 평균 대기 시간(Average Waiting Time) 등을 직접 계산 (5장 전반에 걸쳐 사용한 방식)
 Deterministic modeling with Gantt chart
Deterministic modeling with Gantt chart큐잉 모델(Queueing Model): 리틀의 법칙(Little’s Law) 적용: n = λ × W (n: 평균 큐 길이, λ: 도착률, W: 평균 대기 시간)
 Queueing model using Little’s Law
Queueing model using Little’s Law시뮬레이션 모델(Simulation Model): 실제 프로세스 실행 기록(Trace Tape)을 소프트웨어 시뮬레이터에 입력하여 각 알고리즘별 성능 통계(평균 대기 시간, 응답 시간 등) 산출
 Simulation model with trace tape
Simulation model with trace tape