[OS] 프로세스 관리
프로세스 개념과 메모리 구조, 5가지 상태, PCB, 컨텍스트 스위칭, 스케줄링 큐, 프로세스 생성/종료, Producer-Consumer, IPC, Socket/RPC/RMI
1. 프로세스 개념 및 구성 요소
- 프로세스 정의: 현재 실행 중인 프로그램, 디스크에 설치된 프로그램이 메모리에 올라와 실행되는 상태.
- 용어 구분:
- 배치 시스템(Batch System): 잡(Job), 프로그램과 데이터를 던져주면 사용자와 인터랙션 없이 자동 처리 후 결과만 확인하는 방식.
- 타임 쉐어링 시스템(Time-Sharing System): 프로그램 또는 태스크(Task).
- 프로세스 메모리 구조 (하위 → 상위):
- 텍스트(Text): 프로그램 코드(명령어) 저장 영역.
- 데이터(Data):
- 전역(글로벌) 변수 저장
- 여러 프로세스가 접근 가능한 광역 변수.
- 힙(Heap):
- 실행 중 동적으로 할당·반납되는 메모리 공간
- 위 방향으로 확장.
- 스택(Stack):
- 임시 데이터(함수 파라미터, 리턴 주소, 로컬 변수) 저장
- LIFO(Last In First Out) 구조
- 아래 방향으로 확장.
- 프로그램 카운터(Program Counter): 다음에 실행할 명령어의 주소를 저장.
- 로컬 변수 vs. 글로벌 변수: 로컬 변수는 특정 프로세스 내에서만 접근 가능, 글로벌 변수는 여러 프로세스가 공유 가능.
2. 프로세스 상태 및 PCB
프로세스는 생성부터 종료까지 5가지 상태를 순환하며, 각 상태 전환 시 필요한 모든 정보는 프로세스 제어 블록(PCB, Process Control Block)에 저장된다. PCB는 프로세스당 하나씩 존재하며, 스케줄링·메모리 관리·I/O 상태 등 프로세스 운영에 필요한 모든 정보를 포함한다.
프로세스 5가지 상태:
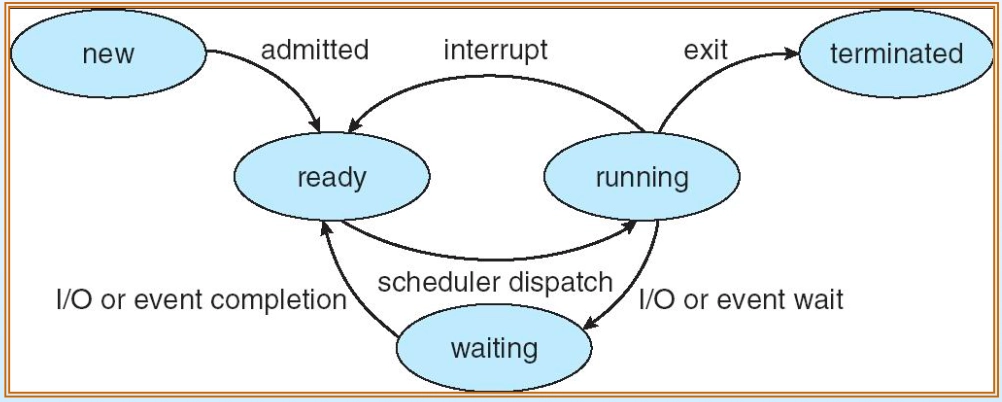 프로세스 상태 전환 다이어그램
프로세스 상태 전환 다이어그램- New: 프로세스가 처음 생성된 상태.
- Ready: 필요한 자원(메모리 포함)을 확보했으나 CPU 할당 대기 중인 상태.
- Running: CPU를 할당받아 실행 중인 상태.
- Waiting: I/O 작업 또는 특정 시그널 대기 중인 상태, 완료 후 Ready 상태로 복귀.
- Terminated: 작업 완료 후 종료된 상태 (정상 종료 또는 강제 종료).
- 상태 전환 흐름:
- New → Ready: 필요 자원 확보 완료
- Ready → Running: CPU 할당
- Running → Waiting: I/O 작업 발생
- Running → Ready: 인터럽트 발생
- Waiting → Ready: I/O 완료 또는 시그널 수신
- Running → Terminated: 작업 완료
PCB 구성 요소:
 PCB(Process Control Block) 구조
PCB(Process Control Block) 구조- 프로세스 상태 (5가지 중 현재 상태)
- 프로그램 카운터 (다음 실행 명령어 주소)
- CPU 레지스터 값
- CPU 스케줄링 정보 (우선순위, 큐 포인터 등)
- 메모리 관리 정보 (베이스/리미트 레지스터, 페이지 테이블, 세그먼트 테이블 — 5장에서 상세 학습 예정)
- 계정 정보 (CPU 사용 시간, 잔여 시간, 프로세스 번호)
- I/O 상태 정보 (사용 중인 I/O 디바이스, 오픈된 파일 목록)
3. 컨텍스트 스위칭 및 오버헤드
컨텍스트 스위칭이란 현재 실행 중인 프로세스를 중단하고 새로운 프로세스를 실행하기 위해 PCB 값을 저장·복구하는 일련의 과정이다. 이 과정 자체는 유용한 작업이 아니므로 오버헤드(Overhead)로 분류되며, 최소화가 요구된다.
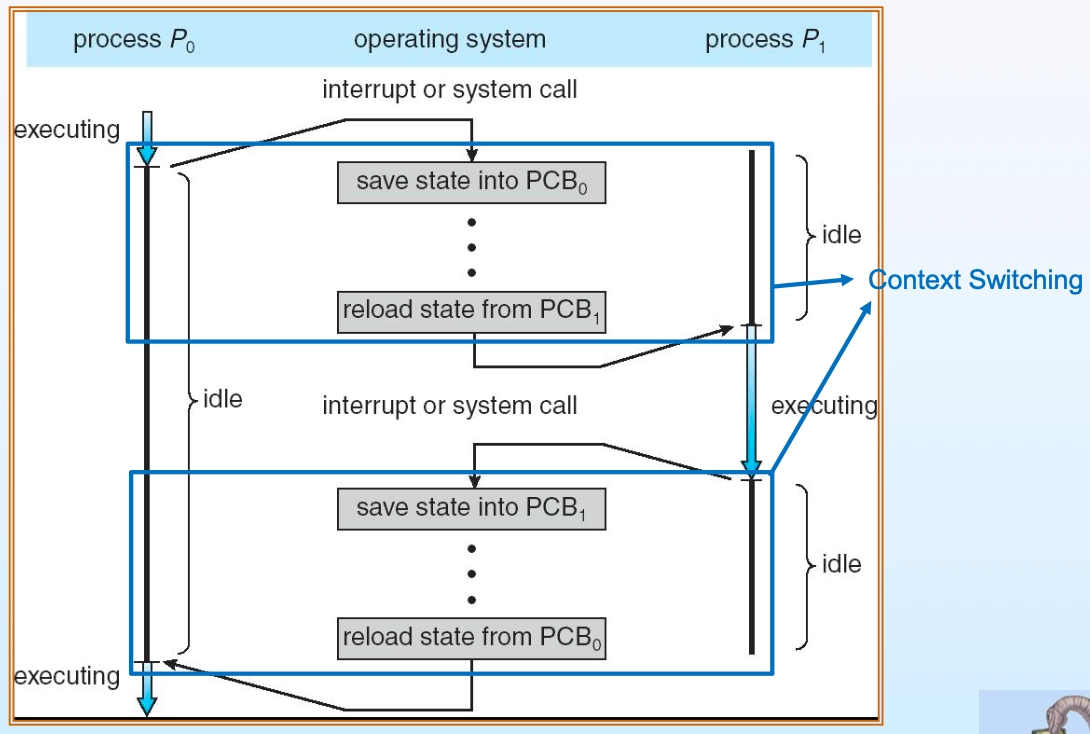 컨텍스트 스위칭 과정
컨텍스트 스위칭 과정
- 컨텍스트 스위칭 절차:
- 현재 실행 중인 프로세스(P0)의 PCB 값을 메모리 또는 레지스터에 저장
- 스케줄링을 통해 다음 실행할 프로세스(P1) 선정
- P1의 PCB 값을 해당 레지스터에 복구(Reload)
- P1 실행 재개
- 오버헤드(Overhead) 개념:
- 메인 작업 수행을 위해 부수적으로 발생하는 비용
- 비유: 가게 운영 시 월세·전기료처럼 메인 작업(물건 매매)에 딸려오는 부대 비용
- 컨텍스트 스위칭 시간은 CPU가 유용한 작업을 하는 시간이 아님 → 최소화 필요
- 오버헤드 감소 방법:
- 메모리 대신 레지스터(Hardware Support) 를 활용하여 PCB 저장·복구 속도 향상
- 레지스터 세트 하나 = PCB 하나에 해당하는 정보 저장
- 레지스터 접근 속도 » 메모리 접근 속도 → 스위칭 시간 단축
4. 프로세스 스케줄링 및 큐
프로세스 스케줄링은 어떤 프로세스를 언제 CPU에 할당할지 결정하는 과정이며, 잡 큐(Job Queue)·레디 큐(Ready Queue)·디바이스 큐(Device Queue)의 세 가지 큐를 통해 관리된다. 스케줄러는 역할과 동작 빈도에 따라 장기(Long-term)·단기(Short-term)·중기(Medium-term) 스케줄러로 구분된다.
세 가지 큐:
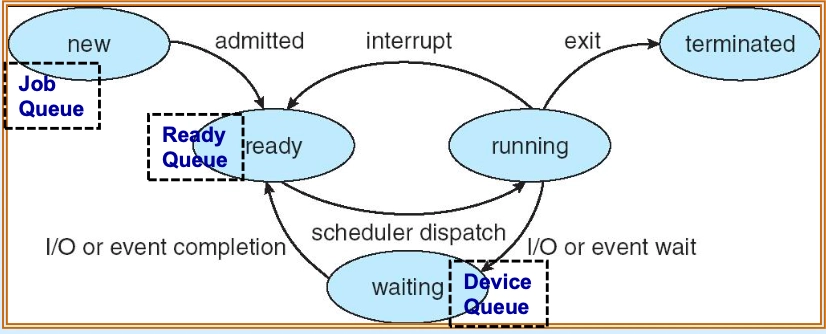 프로세스 스케줄링 큐 구조
프로세스 스케줄링 큐 구조- 잡 큐(Job Queue): 시스템 내 모든 프로그램·프로세스 포함, 디스크에 설치된 것들이 진입.
- 레디 큐(Ready Queue): 필요 자원 확보 완료, CPU 할당 대기 중인 프로세스, 헤드(Head)·테일(Tail) 및 포인터로 연결된 PCB 목록으로 구성.
- 디바이스 큐(Device Queue): 각 I/O 디바이스별 대기 큐, I/O 작업 완료 후 레디 큐로 복귀.
- 세 가지 스케줄러:
- 장기 스케줄러(Long-term Scheduler):
- 디스크 → 메모리 적재 결정
- 멀티프로그래밍 디그리(메모리 상주 프로세스 수) 결정
- 발생 빈도 낮음 → 처리 속도 여유 있음.
- 단기 스케줄러(Short-term Scheduler):
- 레디 큐 → CPU 할당 결정
- 밀리초(ms) 단위로 매우 자주 발생 → 처리 속도 빨라야 함.
- 중기 스케줄러(Medium-term Scheduler):
- 스와핑(Swapping) 관리
- 메모리 공간 확보를 위해 프로세스를 디스크로 내림(Swap Out) 또는 다시 올림(Swap In).
- 장기 스케줄러(Long-term Scheduler):
- 프로세스 유형:
- I/O 바운드 프로세스: I/O 작업 비중이 높아 CPU 이용률이 낮은 패턴
- CPU 바운드 프로세스: CPU 연산 비중이 높아 CPU 이용률이 높은 패턴
- 타임 슬라이스(Time Slice): 프로세스당 CPU 사용 최대 시간, 초과 시 레디 큐로 복귀
5. 프로세스 생성 및 종료
프로세스는 부모(Parent) 프로세스가 자식(Child) 프로세스를 생성하는 트리 구조로 관리된다. 유닉스 계열에서는 fork() 및 exec() 시스템 콜을 통해 프로세스를 생성하며, 종료는 정상 종료(exit)와 강제 종료(abort)로 구분된다.
- 프로세스 생성:
- 부모 프로세스가 자식 프로세스를 생성 → 트리 구조 형성
- 프로세스 ID(PID)는 생성 순서에 따라 증가 (트리 하위, 우측으로 갈수록 PID 증가)
- 자원 공유 옵션: ① 부모·자식 전체 공유, ② 일부 공유, ③ 공유 없이 별도 자원 할당
- 실행 옵션: ① 부모·자식 동시 실행, ② 부모가 자식 종료까지 대기
- 유닉스 시스템 콜:
fork(): 새로운 자식 프로세스 생성, 부모와 동일한 주소 공간 공유.- 반환값 < 0: 오류 발생
- 반환값 = 0: 자식 프로세스 →
exec()호출로 새 주소 공간 및 새 프로그램 할당 가능 - 반환값 > 0: 부모 프로세스 → 자식 완료까지 대기(
wait)
exec()fork()이후 호출- 새로운 주소 공간에 새 프로그램 적재
- 프로세스 종료
- 정상 종료(
exit): 자식이 작업 결과를 부모에게 반환 후 사용 자원을 OS에 반납. - 강제 종료(
abort): 부모가 자식을 강제 종료- 3가지 경우에 해당
- 자식이 할당된 자원 초과 사용 시.
- 자식에게 맡긴 작업이 더 이상 필요 없어진 경우 (예: 웹 브라우저 동영상 창 닫기)
- 부모 프로세스 자체가 종료될 때 → 캐스케이딩 종료(Cascading Termination)(부모 종료 시 모든 자식 프로세스도 연쇄적으로 종료.)
- 3가지 경우에 해당
- 정상 종료(
6. Cooperating Process
- Independent Process: 다른 프로세스의 실행에 의해 영향을 받거나 주지 않는 완전히 독립적인 프로세스
- Cooperating Process: 다른 프로세스의 실행에 의해 영향을 받고, 또 영향을 줄 수 있는 프로세스
- Parent-Child 관계
- Child 프로세스는 Parent에 의해 생성되고, 종료 시에도 Parent에 의해 종료된다.
- 주소 공간 및 자원을 공유할 수 있다.
- Cooperating Process의 4가지 장점
- Information Sharing: 메모리 공간 및 자원을 공유하므로 정보 공유 가능
- Computation Speed-up: 멀티 CPU 환경에서 작업을 divide & conquer 방식으로 분할 처리하여 속도 향상
- Modularity: 유사한 기능을 별도 프로세스로 모듈화하여 관리 용이
- Convenience: 하나의 파일을 열어 편집·프린팅·컴파일링 작업을 동시에 수행 가능
7. Producer-Consumer Problem
Producer-Consumer Problem은 Cooperating Process의 가장 전형적인 패러다임이다. Producer는 데이터를 생성하는 측이고, Consumer는 생성된 데이터를 소비하는 측이다. 둘 사이에는 버퍼(Buffer)가 존재하여 데이터를 임시 저장한다.
- Producer: 컴파일러(어셈블리 코드 생성), 어셈블러(오브젝트 모듈 생성), 웹 서버(HTML·이미지 생성)
- Consumer: 어셈블러(컴파일러가 생성한 코드 소비), 로더(오브젝트 모듈을 메모리에 적재), 웹 브라우저(웹 서버가 제공한 콘텐츠 소비)
- 버퍼 종류: Unbounded Buffer(크기 무제한) vs. Bounded Buffer (고정 크기)
- 공유 자료구조: 크기 10인 원형 배열 버퍼, 변수
in(삽입 위치)과out(추출 위치), 초기값 모두 0 Producer 프로세스 동작
 Producer 프로세스 코드
Producer 프로세스 코드while ((in + 1) % BUFFER_SIZE == out)조건으로 버퍼 가득 참 여부 확인- 버퍼가 가득 차지 않으면
buffer[in]에 데이터 삽입 후in = (in + 1) % BUFFER_SIZE로 업데이트 % BUFFER_SIZE연산을 통해 인덱스가 0~9 범위를 순환하도록 처리- 한계: 이 솔루션은 버퍼 크기 N개 중 최대 N-1개만 사용 가능(마지막 슬롯은 항상 비어 있음)
Consumer 프로세스 동작
 Consumer 프로세스 코드
Consumer 프로세스 코드while (in == out)조건으로 버퍼가 비어 있는지 확인- 비어 있지 않으면
buffer[out]에서 데이터 추출 후out = (out + 1) % BUFFER_SIZE로 업데이트
8. IPC (Inter-Process Communication)
IPC는 프로세스 간 통신을 위한 메커니즘으로, 데이터·정보 교환(communicate)과 실행 순서 동기화(synchronize)를 목적으로 한다. 주요 방식으로는 Shared Memory와 Message Passing 두 가지가 있다.
- IPC 사용 목적
- To communicate: 프로세스 간 데이터 및 정보 교환
- To synchronize (순서화): 프로세스 간 실행 순서 조율
- Message Passing 방식:
send와receive두 가지 오퍼레이션 제공; 고정 크기(fixed-size) 또는 가변 크기(variable-size) 메시지 전송 가능 - Shared Memory 방식: 여러 프로세스가 메모리의 일부 영역을 공유하여 읽기/쓰기로 통신
- Communication Link 구현 시 물리적 고려사항: Shared Memory, 하드웨어 버스, 스위칭, 네트워크 연결 등
- 논리적 고려사항: Direct/Indirect, Synchronous/Asynchronous, Automatic/Explicit Buffer
- Direct Communication:
- 송신자와 수신자를 명시적으로 지정:
send(P, message),receive(Q, &message) - 링크는 자동 설정; 한 쌍의 프로세스 사이에 오직 하나의 링크만 존재; Uni/Bidirectional 선택 가능
- 송신자와 수신자를 명시적으로 지정:
- Indirect Communication (Mailbox/Port):
- 송수신 프로세스 사이에 Mailbox(Port)를 두어 간접 전달:
send(A, message),receive(A, &message) - 각 Mailbox는 고유한 ID를 가지며, 동일 Mailbox를 공유하는 프로세스들 사이에서만 통신 가능
- 송수신 프로세스 사이에 Mailbox(Port)를 두어 간접 전달:
- 동작 순서: Mailbox 생성(create) → send/receive → Mailbox 삭제(destroy)
- 문제 상황: P1이 send 시 P2, P3가 동시에 receive 실행 → 수신자 불명확
- 해결 방안 3가지:
- 링크는 최대 2개의 프로세스 사이에서만 형성
- 어느 한 순간에 오직 하나의 프로세스만 receive 실행 가능
- 시스템이 랜덤으로 수신자를 선택하고 sender에게 통보
- Synchronization (Blocking vs. Non-blocking):
- Blocking (Synchronous): 상대방이 준비될 때까지 대기; 버퍼 크기 = 0일 때 해당; 두 프로세스가 만나는 것을 Rendezvous라 표현
- Non-blocking (Asynchronous): 상대방 상태와 무관하게 동작; 버퍼가 있어야 가능; sender는 버퍼에 쓰고 즉시 다른 작업 수행; receiver는 원할 때 버퍼에서 읽음(비어 있으면 null 반환)
- 버퍼 크기에 따른 분류
- Zero capacity → Blocking/Synchronous (Rendezvous)
- Bounded capacity → 버퍼가 찰 때까지 non-blocking, 이후 blocking
- Unbounded capacity → Non-blocking/Asynchronous
9. 클라이언트-서버 커뮤니케이션: Socket, RPC, RMI
- Socket
- 커뮤니케이션을 위한 엔드포인트(Endpoint)로 정의
- 구성:
IP 주소 : 포트 번호(예:161.25.19.8:80) - 통신은 한 쌍의 소켓(클라이언트 소켓 ↔ 서버 소켓) 사이에서 이루어짐
- 잘 알려진 포트 번호
- 80: 웹 서비스(HTTP)
- 23: Telnet (원격 시스템 접속)
- 21: FTP (파일 전송)
- 예시: 클라이언트
146.86.5.20:1625↔ 웹 서버161.25.19.8:80 RPC (Remote Procedure Call)
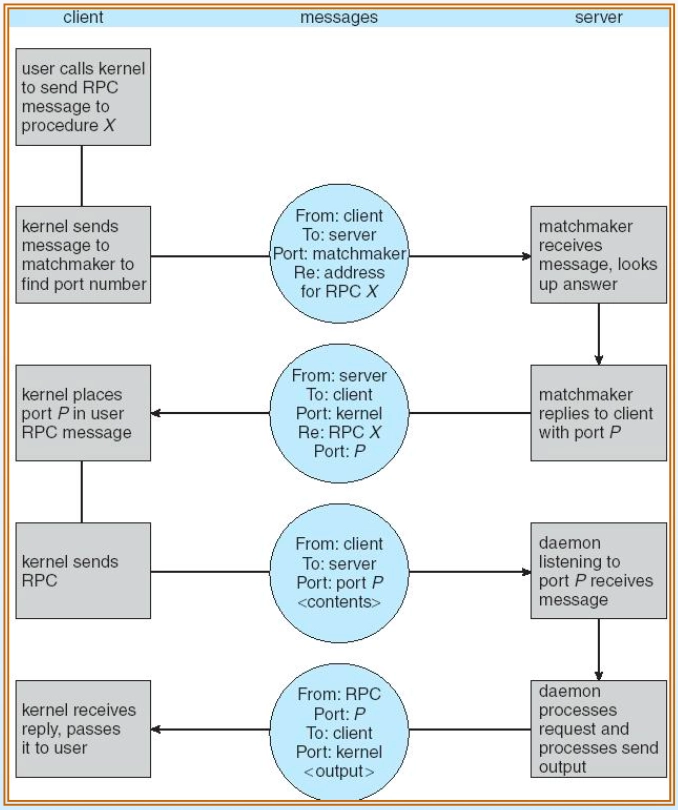 RPC(Remote Procedure Call) 동작 과정
RPC(Remote Procedure Call) 동작 과정- 원격으로 떨어진 프로세스의 프로시저(함수)를 로컬 함수 호출처럼 실행하는 메커니즘
- Stub(스텁): 클라이언트 측 프록시 역할; 서버 위치 파악, 프로시저명·파라미터를 패키징하여 전송
- Skeleton: 서버 측 스텁; 메시지 수신 후 언패킹하여 해당 프로시저 실행, 결과를 클라이언트로 반환
- 동작 순서
- 클라이언트가 Matchmaker 포트를 통해 원하는 프로시저(rpcX)의 포트 번호 질의
- Matchmaker가 포트 번호 P를 응답
- 클라이언트가 포트 P로 RPC 호출 요청
- 서버의 Daemon이 요청 수신 후 처리, 결과값 반환
- 커널이 결과를 사용자 프로그램에 전달
RMI (Remote Method Invocation)
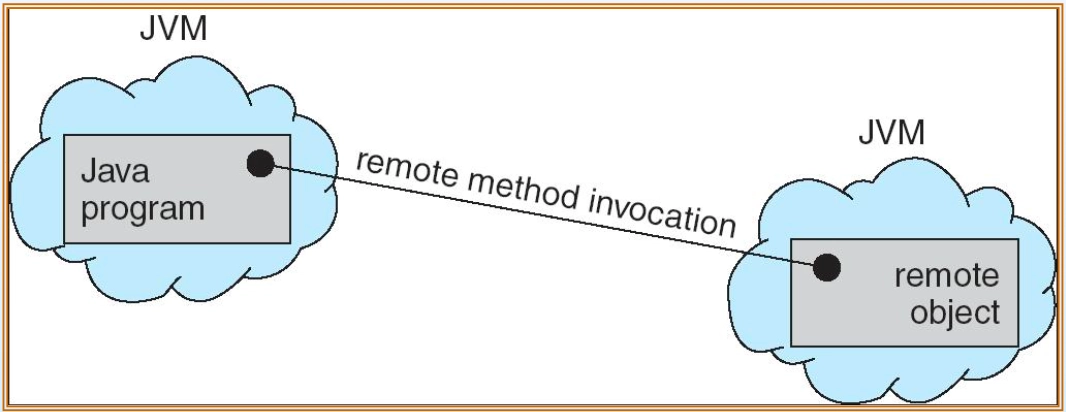 RMI(Remote Method Invocation) 동작 과정
RMI(Remote Method Invocation) 동작 과정- RPC와 목적은 동일하나 객체 지향(Java JVM) 환경에서 사용, 원격 객체의 메서드를 호출
- 동작 예시: 클라이언트 스텁이
sum(a, b)메서드명과 파라미터를 패키징 → 서버 Skeleton이 수신·언패킹 후sum(ObjectX, ObjectY)실행 → 결과(boolean: true/false) 패키징 → 클라이언트 스텁이 수신·언패킹 후 사용자 프로세스에 전달 - RPC와의 차이:
- 메서드 호출(Method Invocation) vs. 프로시저 호출(Procedure Call)
- 본질적 메커니즘은 유사