[OS] 스레드와 멀티스레딩
스레드 기본 개념, User/Kernel level threads, Many-to-One/One-to-One/Many-to-Many 모델, Threading Issues, Pthreads, Linux/Windows 스레드
1. Threads 기본 개념 및 정의
프로세스는 디스크에 설치된 프로그램이 메모리에 올라와 실행되는 단위. 이 프로세스는 더 작은 실행 단위인 스레드(Thread)로 분할될 수 있다. 스레드는 CPU 이용의 가장 기본적인 단위로, 경량급 프로세스(Lightweight Process)라고도 불린다. 하나의 프로세스 내에는 반드시 최소 하나의 스레드가 존재하며, 스레드로 분할되지 않은 프로세스는 헤비웨이트 프로세스(Heavyweight Process)라 한다.
- 스레드의 구성 요소: Thread ID, program counter(PC), register set, stack space
- Peer Thread: 동일 프로세스에서 파생된 스레드들로, 코드 섹션·데이터 섹션·운영체제 자원(파일 등)을 공유함
- Task: 코드 섹션 + 데이터 섹션 + OS 자원을 합쳐 일반적으로 Task라 부르기도 함
- 프로그램 카운터의 역할: 각 스레드가 어디까지 실행됐는지를 나타내며, 다음에 실행할 인스트럭션의 주소를 저장함
- 싱글 스레드 vs. 멀티 스레드: 싱글 스레드 프로세스는 하나의 실행 흐름만 존재하고, 멀티 스레드 프로세스는 코드·데이터·파일을 공유하면서 각 스레드가 독립적인 레지스터와 스택 공간을 보유함
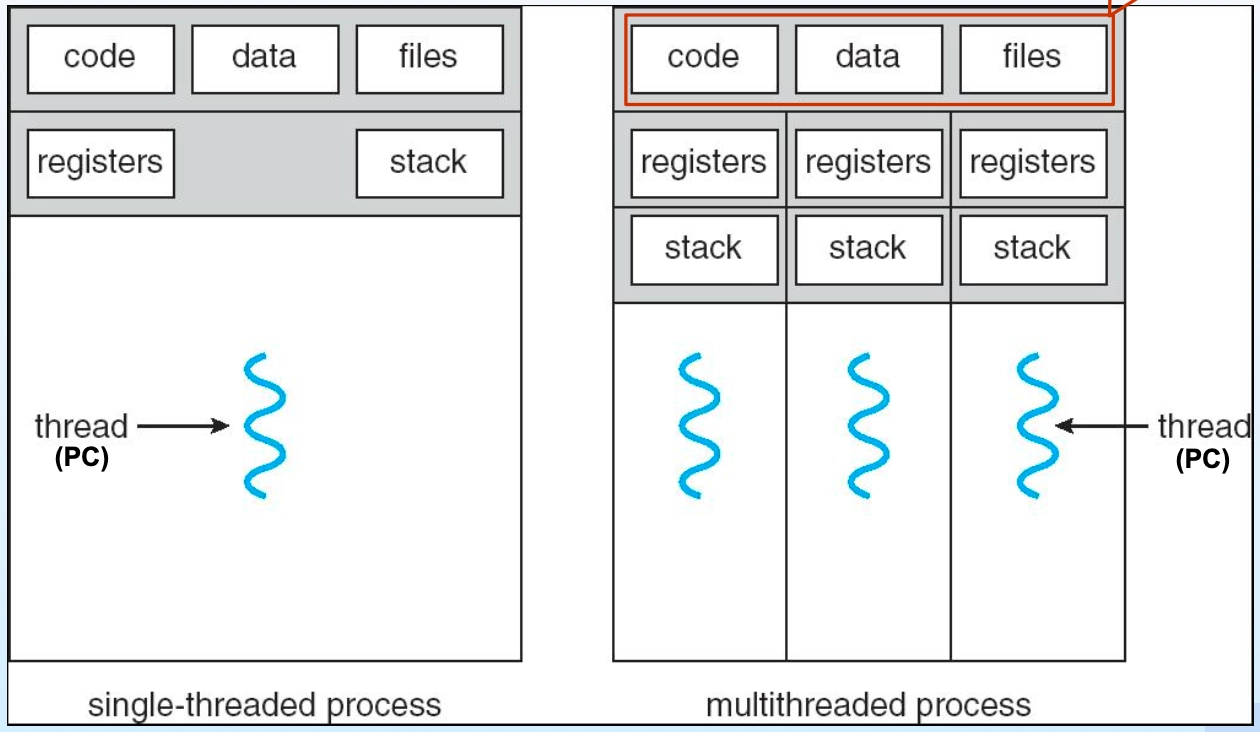 싱글 스레드 프로세스와 멀티 스레드 프로세스의 구조 비교
싱글 스레드 프로세스와 멀티 스레드 프로세스의 구조 비교
멀티스레드의 장점
- 반응성(Responsiveness): 한 스레드가 블록(I/O 대기 등)되어도 다른 스레드가 CPU를 점유하여 처리 지속 가능 (Producer-Consumer 예시)
- 자원 공유(Resource Sharing): 피어 스레드 간 코드·데이터·OS 자원 공유로 효율적 운용
- 경제성(Economy): 별도의 자원 세트를 각 스레드가 보유하지 않으므로 자원 절약
- 멀티프로세서(MPA) 이용률 향상: 스레드 단위로 일감이 늘어나 여러 CPU가 동시에 각기 다른 스레드를 처리 가능
멀티 프로세스 vs. 멀티 스레드 비교
| 항목 | 멀티 프로세스 | 멀티 스레드 |
|---|---|---|
| 독립성 | 각 프로세스 독립 동작 | peer 스레드 간 비독립(공유) |
| 구성 요소 | PC, 레지스터 셋, 스택 포인터 | PC, 레지스터 셋, 스택 공간 |
| 메모리 공간 | 각자 별도 메모리 사용 | 동일 메모리 공간 공유 |
| 보호 필요성 | 상호 보호(메모리 침범 방지) 필요 | 동일 프로세스 파생이므로 보호 불필요 |
2. User Level Threads vs Kernel Level Threads
스레드는 구현 위치에 따라 다음 3가지로 분류된다.
- User level threads
- Kernel level threads
- Hybrid(양쪽 모두 지원)
CPU는 커널 레벨 스레드만 인식하며, 유저 레벨 스레드가 실제로 처리되려면 반드시 커널 레벨 스레드에 매핑되어 일감을 전달해야 한다.
- User level threads:
- POSIX API 등 사용자 라이브러리(API)를 통해 생성·종료·중지·재개 관리
- OS(커널)와 무관하게 동작하므로 컨텍스트 스위칭이 매우 빠름
- 부담 없이 다수 생성 가능(컴파일 시 결정 가능)
- 단점: CPU 스케줄링 시 유저 레벨 스레드 개수가 보이지 않아 불공정 스케줄링(Unfair Scheduling) 발생 가능
- Kernel level threads:
- 커널이 직접 지원하며, 생성 시 자원(메모리 등) 소모 및 오버헤드 발생
- 시스템 자원을 고려한 최적 개수만 유지하는 방식으로 운용
- 지원 OS: Solaris, Linux, Windows, macOS 등
- 컨텍스트 스위칭 시 커널 호출 필요 → 상대적으로 느림
- CPU에 직접 보이므로 공정한 스케줄링 가능
- Hybrid: 유저 레벨과 커널 레벨 모두 지원하는 현대 OS의 일반적 방식
3. Multithreading Models
유저 레벨 스레드와 커널 레벨 스레드 간의 매핑 방식에 따라 세 가지 모델로 분류된다. 각 모델은 성능, 공정성, 자원 효율성 측면에서 서로 다른 장단점을 가진다.
Many-to-One (다대일) 모델
- 여러 유저 레벨 스레드 → 하나의 커널 레벨 스레드에 매핑
- 경합 발생, 커널 스레드가 블록되면 전체 CPU가 유휴 상태가 됨
- 단점: 병렬 처리 불가, 블록 시 전체 중단
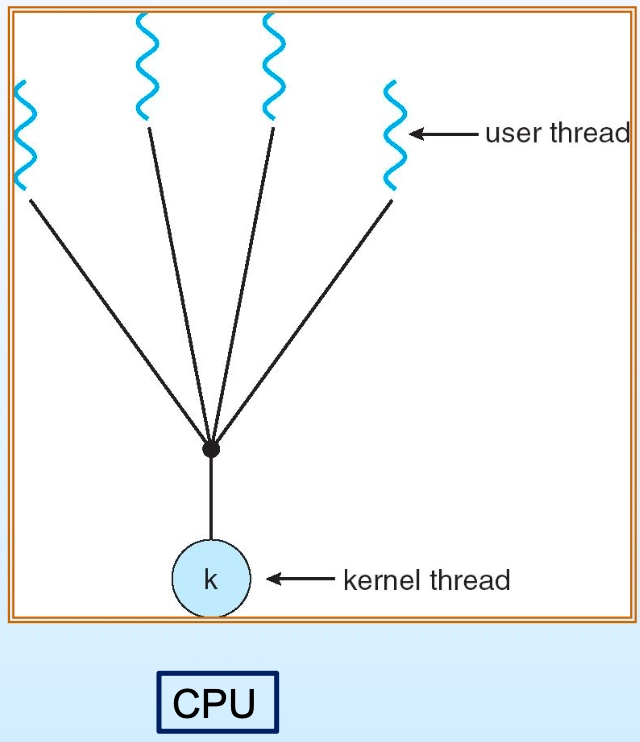 Many-to-One 모델: 여러 유저 스레드가 하나의 커널 스레드에 매핑
Many-to-One 모델: 여러 유저 스레드가 하나의 커널 스레드에 매핑
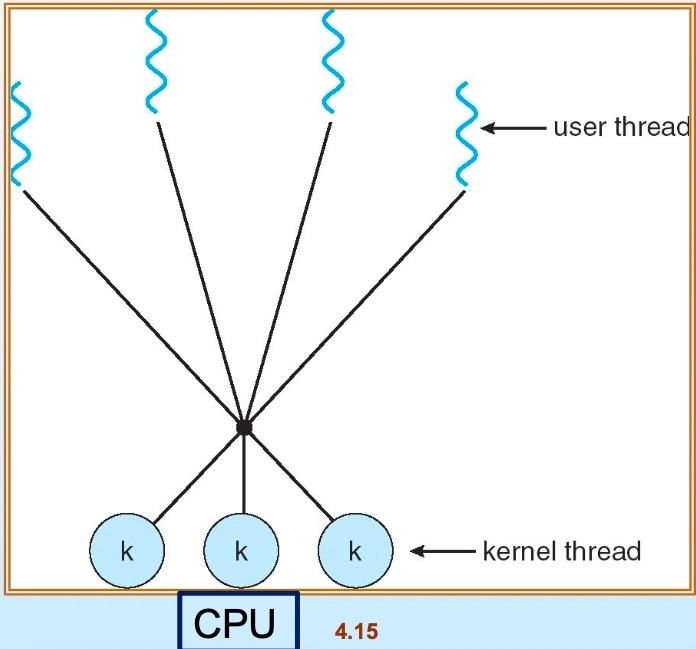
One-to-One (일대일) 모델
- 유저 레벨 스레드 하나 ↔ 커널 레벨 스레드 하나 1:1 매핑
- 경합 없음, 한 스레드 블록 시 다른 스레드 처리 가능 → 병렬성 향상
- 단점: 유저 레벨에서 100개 생성 시 커널 레벨에서도 100개 필요 → 자원 오버헤드 과다
- 지원 OS: Windows XP 등
 One-to-One 모델: 유저 스레드와 커널 스레드가 1:1 매핑
One-to-One 모델: 유저 스레드와 커널 스레드가 1:1 매핑
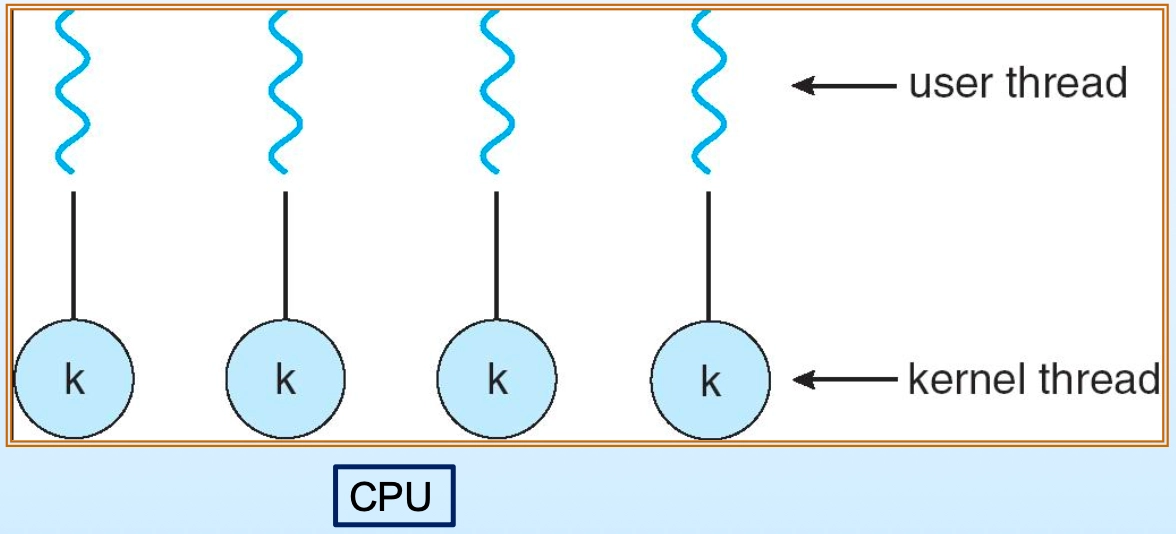
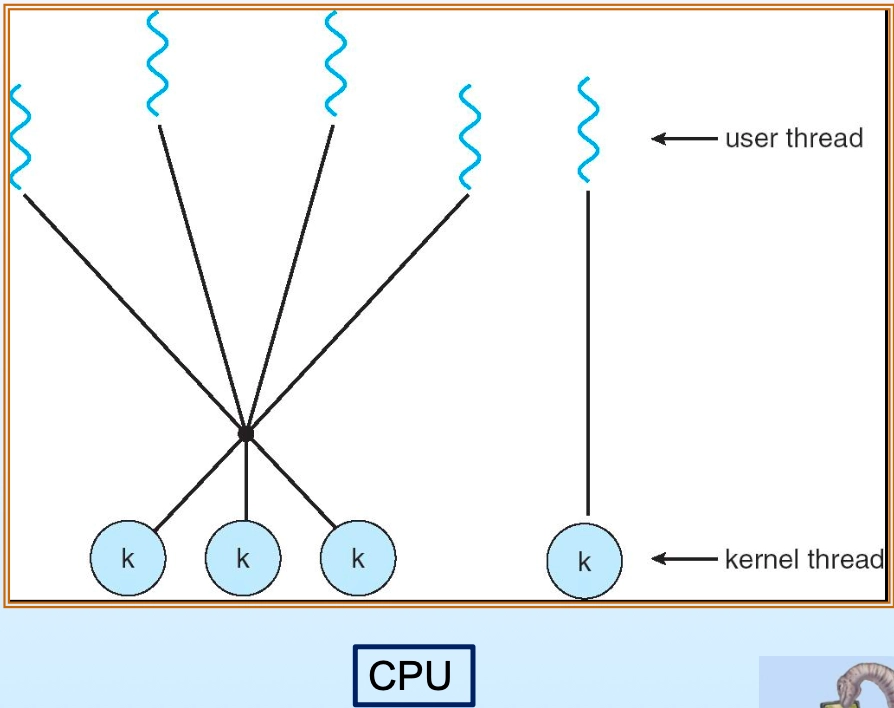
Many-to-Many (다대다) 모델
- 다수의 유저 레벨 스레드 → 적정 개수의 커널 레벨 스레드에 매핑 (user threads 개수 > kernel threads 개수)
- 커널 레벨 스레드 최적 개수 유지 가능(예: 50개 고정)
- 단점: 중요한 작업이 경합에서 계속 밀릴 수 있음
 Many-to-Many 모델: 다수의 유저 스레드가 적정 수의 커널 스레드에 매핑
Many-to-Many 모델: 다수의 유저 스레드가 적정 수의 커널 스레드에 매핑
Two-Level (투 레벨) 모델 (하이브리드)
- Many-to-Many + One-to-One 혼합 운용
- 중요 작업은 1:1 모델 적용, 일반 작업은 다대다 모델 적용
- 성능과 자원 효율성을 동시에 확보
 Two-Level 모델: Many-to-Many와 One-to-One의 하이브리드
Two-Level 모델: Many-to-Many와 One-to-One의 하이브리드
유저 레벨 스레드는 부담 없이 만들 수 있지만, 커널 레벨 스레드는 하나 만들 때마다 자원이 필요하다.
4. Threading Issues
스레드를 실제 시스템에서 운용할 때 고려해야 할 6가지 주요 이슈가 있다. 각 이슈는 스레드의 생성, 종료, 신호 처리, 자원 관리, 데이터 저장, 커뮤니케이션과 관련된다.
fork() & exec()
- 멀티스레드 환경에서
fork()호출 시, 호출한 스레드만 복제할지 전체 피어 스레드를 복제할지가 이슈 fork()직후exec()가 이어지면 호출 스레드만 복제, 그렇지 않으면 전체 피어 스레드 복제
Thread Cancellation
- 비동기식(Asynchronous) cancellation: 즉시 강제 종료 → 작업 결과 손실, 공유 변수 불일치 위험
- 지연(Deferred) cancellation: 코드 내 캔슬레이션 포인트(Cancellation Point)를 설정하여, 해당 지점 도달 시에만 종료 → 작업 결과 안전 보존, 공유 변수 무결성 유지 → 주로 이 방식 사용
Signal Handling
- 인터럽트/시그널 발생 시 처리 담당 스레드 지정 방식 4가지:
- 해당 작업을 수행 중인 스레드에게 전달
- 프로세스 내 모든 스레드에 브로드캐스트 → 여유 있는 스레드가 처리
- 전담 스레드 그룹(전담반) 지정
- 특정 스레드 하나를 전담 지정(다른 작업 금지)
Thread Pool
- 시스템 자원을 고려한 최적 개수의 커널 레벨 스레드를 미리 생성하여 풀(Pool)에 대기
- 일감 발생 시 풀에서 스레드를 꺼내 매핑 → 처리 완료 후 풀로 반환
- 장점: 스레드 생성 오버헤드 제거, 최적 개수 유지
Thread-Specific Data
- 피어 스레드 간 공유 데이터 외에, 각 스레드가 고유 데이터를 저장할 수 있어야 함
- 예: 은행 트랜잭션 처리 시 각 스레드가 서로 다른 계좌번호·금액 등 고유 데이터 보유 필요
- 스레드 풀 환경에서 특히 중요(미리 생성된 스레드에 고유 데이터 저장 공간 필요)
Scheduler Activation
- 왜 필요한가?
- M:M 모델에서의 근본적 문제:
유저 스레드 100개를 관리하는데, 커널 스레드가 몇 개 필요한지 누가 결정하지? - 유저 레벨 라이브러리는 커널 상황을 모름 (어떤 스레드가 블락됐는지)
- 커널은 유저 스레드 존재를 모름 (몇 개가 실행 대기 중인지)
→ 서로 정보가 없으니까 커뮤니케이션 채널이 필요 = Scheduler Activation
- M:M 모델에서의 근본적 문제:
- 유저 레벨 스레드 라이브러리와 커널 간 업콜(Upcall) 방식으로 커뮤니케이션
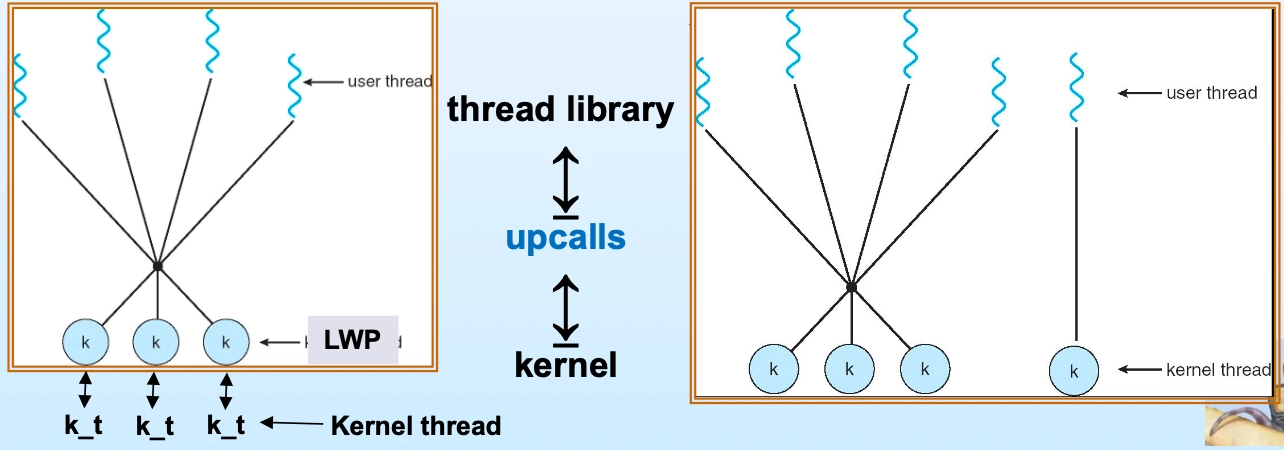 Scheduler Activation: 유저 레벨 라이브러리와 커널 간 Upcall 통신
Scheduler Activation: 유저 레벨 라이브러리와 커널 간 Upcall 통신
- Upcall? 커널이 유저 라이브러리한테 먼저 알림을 보내는 것. 보통은 유저 → 커널 방향(시스템 콜)인데, 여기선 반대로 커널 → 유저 라이브러리 방향으로 이벤트를 통보
- 스레드가 I/O로 블락될 때
- 유저 스레드 A가 I/O 시스템 콜 호출
- 커널: “어, A가 블락됐네. 라이브러리한테 알려야겠다” → upcall 발생
- 커널: LWP(가상 CPU) 하나 새로 줌
- 유저 라이브러리: 새 LWP 받아서 대기 중인 스레드 B를 실행시킴
- 나중에 A의 I/O 완료되면 → 커널이 또 upcall로 알림
- 유저 라이브러리: A를 다시 runnable 상태로 만들어서 스케줄링
- CPU 바운드 작업 → 커널 레벨 스레드 수 증가
실행할 유저 스레드는 10개인데 LWP가 2개뿐
→ 유저 라이브러리가 커널한테 “LWP 더 줘!” 요청 → 커널이 LWP(=커널 스레드) 추가 할당
LWP(Lightweight Process): 유저 스레드 라이브러리가 제공하는 가상 CPU 개념. 유저 레벨 스레드와 커널 레벨 스레드 사이에 위치하며 1:1로 커널 스레드와 매핑
1 2 3 4 5
[ 유저 스레드들 ] ← 유저 레벨 라이브러리가 스케줄링 ↕ (upcall) [ LWP들 ] ← 가상 CPU (중간 다리 역할) ↕ [ 커널 스레드들 ] ← 커널이 실제 CPU에 스케줄링
5. Pthreads, Windows XP, Linux
실제 운영체제에서 스레드를 어떻게 구현하고 관리하는지를 간략히 살펴본다. 각 OS는 스레드 관리 방식과 지원 모델에서 차이를 보인다.
- Pthreads:
- POSIX API에서 제공하는 스레드 관련 라이브러리의 명칭
- 스레드 생성·종료·중지·재개 등 관리 기능 제공
- UNIX, Linux, macOS 등 대부분의 POSIX 호환 OS에서 사용
- Windows XP:
- One-to-One 매핑 지원
- 스레드 구성 요소: 스레드 ID, 레지스터 셋, 유저 스택 + 커널 스택(분리), 프라이빗 데이터 스토리지(Thread-Specific Data)
- 스레드 컨텍스트 = 레지스터 컨텍스트 + 프라이빗 데이터 스토리지
- Linux 스레드:
- 스레드보다 Task라는 용어를 주로 사용
clone()시스템 콜을 이용하여 새로운 스레드(child task) 생성- Java(JVM) 스레드 상태: New → Runnable → Waiting/Blocked → Terminated (4가지 상태)